
Since the beginning of November 2018 and the start of the Yellow Vest protests, France has experienced a three-fold unprecedented social movement. This mobilisation took place outside any existing organisational framework (i.e. trade unions, political parties or associations). It was also unprecedented in its longevity, as national demonstrations have been held on a weekly basis since Saturday 17th of November 2018, until the European elections in 2019. Last but not least, the multiplicity of channels of expression it used were unknown in France: social networks, the displaying of yellow vests on car windshields, recurring weekly demonstrations, attempts to form a list for the upcoming European elections and so on.
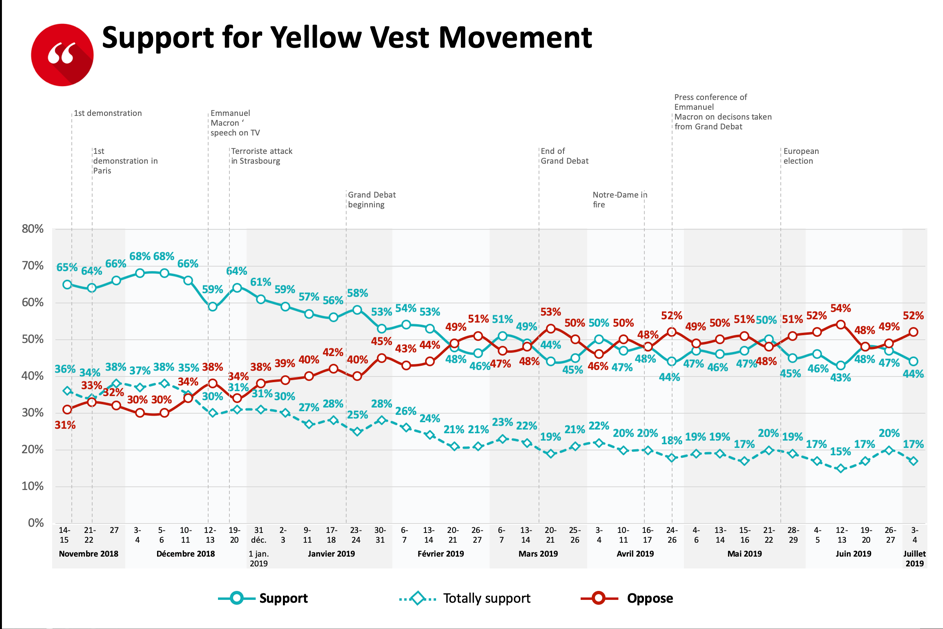
Since the social movement began, it has enjoyed strong public support; it reached 68% in favour ratings in November and December 2018, then dropped to around 58% until the end of January 2019. From February 2019 to present, it stabilised to around 45-48% of support, which is still incredible for a protest that began nine months ago.
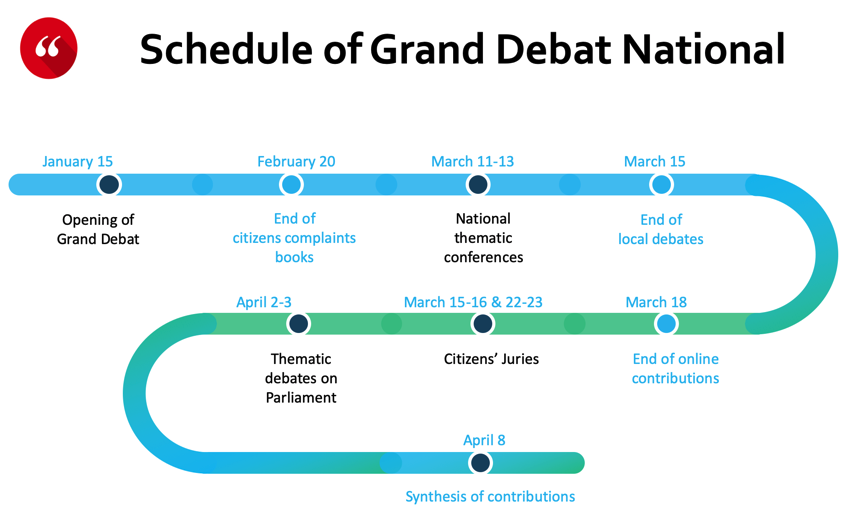
To answer to this protest, President Macron announced in January that a “Grand Débat National” will be held all over the country. A series of town hall-style gatherings were scheduled across France, where citizens could speak to their local mayors about their concerns. During two months, citizens were also allowed to make proposals online at granddebat.fr. Additionally, in March, the government held “regional citizen conferences”, intended to summarise the main findings from the sessions and establish concrete proposals for Macron to consider.
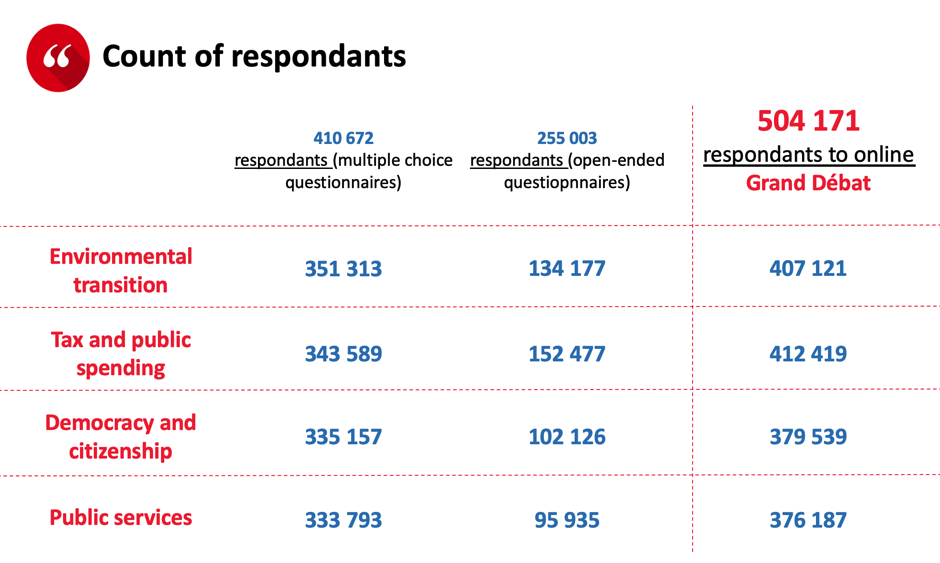
OpinionWay was in charge of analysing the data collected on the online platform granddebat.fr. Two major challenges were faced. First, we had only two-and-a-half weeks following the end of the debate to deliver the results. Second was the huge volume of data, with more than 70 open-ended questions, 1,363,852 contributions and more than 5 million verbatims written by contributors overall.
The government advertised Grand Débat a lot in order to involve the population and increase contributions. The participation curve was unusual, and a peak was reached again during the last week, which we never notice usually for this kind of online consultation. In the end, more than 500,000 citizens contributed to the website regarding at least one issue, with more than 255,000 respondents to open-ended questionnaires.
There was no demographics on the questionnaire, so it was a challenge to analyse who the contributors actually were. However, we thought it was a decisive point to understand the data better. The only thing we could use was the postal code. We decided to cross this information with census data in order to create maps and revenue indicators, to verify whether the respondent population matched the general French population, as purchasing power was one of the most important issues for the yellow vests.
To analyse open-ended questions, regarding to the volume of data and the short period to deliver results, we decided to use AI technology. We used a platform to access software dedicated to text analysis. Developed after several years of research around big data technologies, semantics and machine learning, the platform automatically detects and analyses standard text elements (e.g. person, company, concept, event, organisation, location, etc.), and can also integrate project specific vocabulary.
This solution makes it possible to automatically process large quantities of texts to draw quantitative analyses with a qualitative dimension. It also offers data analysis, segmentation and data visualisation capabilities. Particularly suited to the analysis of open questions resulting from the consultations, which can include a very large number of verbatims, this solution proposes many keys of analysis for the open questions, with a finesse that does not have all the tools of textual analysis.
Semantic enrichment consists of recognising different signifying elements in a text. This involves first detecting named entities, which are proper names or very specific common names. It is then necessary to recognise the concepts, which are phrases of several words having a significant interest. At that stage, human intervention was necessary to decide whether the concept was significant in the context of this analysis or not, and eventually to correct it. Validating renamed identified AI concepts, to make sure they were relevant, was a huge undertaking. After every human intervention, we screened data with AI again to make it more efficient, to eliminate statistical noise and to reduce unclassified verbatims.
Then, for each issue, we tried to summarise the main findings, regarding volume and themes discussed by respondents.
In the end, this mode of analysis was conducted under the constraints of rules enacted by the government, as well as under the protection of a college of guarantors, composed of specialists in public debate and data analysis.
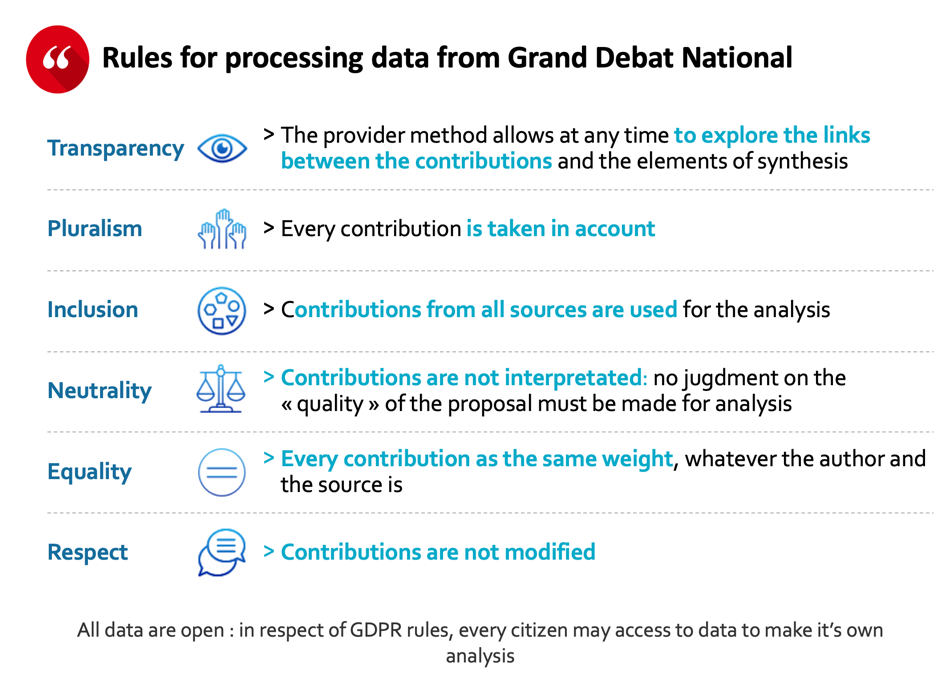
All the data collected was open-access (and is still) to allow all citizen to make their own analyses, which is not usual in our daily business.

About the Author:
Bruno Jeanbart, Deputy Managing Director at OpinionWay, France.